
The IENDP proposed in this paper applies the mechanical statistical foundation proposed by Yuille et al. and Rose et al.49,50 to the ENA. By applying the maximum entropy principle, we determine the optimal probability distribution for assigning data points to clusters. Through a gradual temperature reduction process, the system progressively reaches local minima of the energy function. As the temperature approaches zero, the network converges to a stable saturated state, yielding the final clustering solution.
The key distinctions between the proposed IENDP and the original elastic net clustering algorithm NENA are as follows: first, in the proposed algorithm, according to the aim of clustering, a squared distance cost function is designed and introduced into the energy function of elastic net, and the penalty item of the energy function in the original elastic net is removed, which could improve the clustering solution quality and reduce the calculation amount. Second, a novel dynamic parameter strategy is presented and \(\mu (t)\) is introduced into the energy function, which can make the energy function minimized rapidly, enhance the space searching ability of the network and reduce the computation time, thereby increasing the model’s capacity to escape from local minima. At the same time, the parameter tuning and parameter sensitivity problems of the elastic net could be alleviated.
In the following, we conduct multiple experiments on some datasets to analyze the impact of different parameters, the dynamic parameter strategyand the novel energy function in IENDP. The datasets include a synthetic dataset (Dataset A) containing 4000 data points and two real-world dataset Sym and Waveform. The artificially synthesized dataset is a non-standard dataset, so SED (Eq. 1) is used as the evaluation indicator for the clustering quality of the algorithm. When the SED is smaller, the clustering quality is better. For real-world datasets, accuracy is used as an evaluation indicator of the clustering quality of the algorithm. The larger the accuracy, the better the clustering quality.
Accuracy is a commonly used evaluation indicator in clustering, defined as follows:
$$\begin{aligned} Accuracy =\frac{\sum _{i=1}^n N_i}{N} \end{aligned}$$
(11)
where \(N_i\) is the number of data points that are correctly classified in a cluster after clustering, and N is the total number of all data points in the data set.
In the proposed method, based on a large number of related experiments, the ranges of parameters \(\mu (t)\) and \(\eta\) are: \(0.0001 \le \mu (t) \le 0.01\) and \(0.0001 \le \eta \le 100\), respectively. Parameters \(\mu (t)\) and \(\eta\) should be adjusted according to the scale of the datasets in the recommended ranges mentioned above. And the value of \(\theta\) is set as a fixed value 0.001. The parameter setting method of NENA is described in detail in the corresponding paper34, and in the two tested experiments the parameter values of NENA are set strictly as described in paper34. In the proposed IENDP , we set parameters as \(\mu (t)=0.001\), \(\eta =3\) for dataset A, \(\mu (t)=0.001\), \(\eta =1\) for dataset Sym and \(\mu (t)=0.001\), \(\eta =55\) for dataset Waveform. In addition, in order to observe the effect of the proposed dynamic parameter strategy on the network operation, we also compare the IENFP (IENDP with fixed parameter) and the FAENC1 (Elastic net with the novel energy function). The parameters of IENFP are set as same as the IENDP and the parameters of FAENC1 are set as described in corresponding paper51.
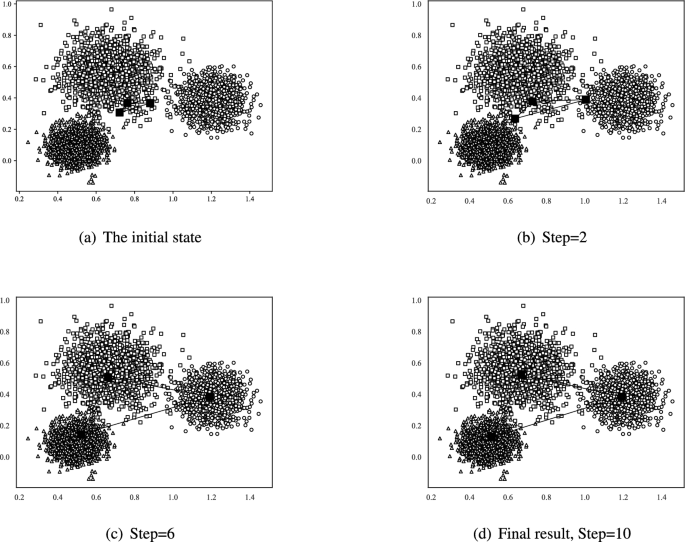
The annealing process of IENDP algorithm for solving dataset A.

Evolution diagram of IENDP algorithm solving process on dataset Waveform.

Evolution diagram of FAENC1 algorithm solving process on dataset Waveform.
Temperature-related parameter \(\eta\) analysis
The temperature-related parameter \(\eta\) is inversely proportional to the temperature T during the simulated annealing process. Therefore, as the temperature decreases, \(\eta\) will continuously increase. For observing the cluster annealing process of the proposed method, we plot the evolution process for clustering of IENDP algorithm on a synthetic dataset (Dataset A) in the first and second dimensions in Fig. 1. The experiment was configured with three elastic nodes. Data points belonging to distinct clusters are denoted by hollow markers (squares, circles, and triangles), while elastic nodes are represented by solid squares.
From Fig. 1 we can see that the elastic band is initialized as a fixed small circle in the first and second dimensions. As the temperature goes down, that is, the parameter \(\eta\) increases, the elastic band gradually spreads toward the data points. Using the maximum entropy principle, the maximum probability distribution of data points can be obtained step by step and the data points can be divided into a certain cluster finally. It can be seen that at iteration 6, the elastic nodes have basically diffused into the corresponding clusters. At iteration 10, the SED value drops to the lowest value of 765.61, indicating that the system tends to be stabilized and reach an equilibrium state.
Dynamic parameter \(\mu (t)\) analysis
The proposed dynamic parameter strategy is as follows: in the early stage of network operation, \(\mu (t)\) is set as a relatively high value, which strengthens the attractions from data points to the elastic nodes, including isolated or widely distributed points. The attraction of data points to each elastic node increases, thereby preventing the network from ignoring the influence of these isolated points on the clustering results, consequently accelerating the movements of elastic nodes towards the optimal cluster centers. Furthermore, this enhances the space searching ability of the network and increases IENDP’s capacity to find optimal solutions. As the network operates, \(\mu (t)\) continuously decreases. The value of \(\mu (t)\) will gradually drop within the appropriate range of the network, and the displacement of each elastic node gradually decreases, providing sufficient time for network to determine the maximum entropy probability distribution based on the appropriate parameter values. Then, the elastic net can match the corresponding cluster centers within the appropriate range of \(\mu (t)\) values, enabling the elastic nodes to search in the possible optimal position area. Thus, the network can achieve better solution quality. In the convergence stage, with the decreasing of \(\mu (t)\), the attractions from data points to each elastic node decline rapidly, which could accelerate the convergence process. In a word, by incorporating the dynamic time parameter, the expansion and convergence process of the network is effectively accelerated. The ability to search for the probability distribution that maximizes entropy is increased, and the clustering solution quality can be improved significantly.
To verify the above analysis, we conduct an experiment the real-word dataset Waveform. We plotted the evolution of the clustering results of the IENDP and FAENC1 at different stages of its operation (in the first and second dimensions), as shown in Figs. 2 and 3.
From Figs. 2 and 3, it can be seen that the IENDP with dynamic parameter \(\mu (t)\) achieves the optimal clustering accuracy of 0.8554 at step 11. In contrast, FAENC1 requires 22 steps to obtain the best clustering result, but its clustering accuracy is only 0.6324. The accuracy of IENDP is 35.26% higher than that of FAENC1. It can be concluded that compared with the FAENC1 with the same new energy function, IENDP can obtain a better solution in fewer iterations.
Furthermore, Figs. 2 and 3 illustrate that under the influence of the dynamic parameter \(\mu (t)\), the network can expand rapidly in the initial stage and can quickly reach the corresponding cluster. The rapid expansion of the elastic nodes ensures that the network does not ignore the attraction of isolated or discrete points to the elastic nodes. And it does not ignore the influence of these attractions on the final clustering result, thereby optimizing the clustering result. Therefore, the problem of discrete points is solved. As the network operates, the parameter \(\mu (t)\) gradually decreases to an appropriate range, enabling the network to achieve better clustering results. During the convergence stage of the network, the elastic nodes have already reached the optimal cluster center or are very close to it. Further reducing \(\mu (t)\) can accelerate the convergence of the network.
Analysis of the combination of the energy function and dynamic parameter

The SED and energy variation curve of IENDP, IENFP and NENA on dataset A.

The SED and energy variation curve of IENDP, IENFP and NENA on dataset Sym.
To verify the effectiveness and the acceleration effect of the energy function and dynamic parameter strategy proposed in this paper, we compare the proposed IENDP with NENA and IENFP. We plot the variation curves of SED and energy values of these three methods for solving dataset A in Fig. 4a, b. And the variation curves of SED and energy values of these three methods for dataset Sym are plotted in Fig. 5a, b. In Figs. 4 and 5, different methods are represented with different colors and shapes (IENDP: blue triangles, IENFP: black circle, NENA: green star).

The evolution of the coordinate changes of the representative neurons selected in NENA, IENFP and IENDP for clustering on dataset A from iteration 0 to 110.

The evolution of the coordinate changes of the representative neurons selected in NENA, IENFP and IENDP for clustering on dataset Sym from iteration 0 to 200.
From Figs. 4 and 5 we can see clearly that the proposed IENDP converges to the saturated state and acquire the best solution using fewer iterations, and the energy function decreases faster than the other two compared algorithms. In Fig. 4a, it can be seen that the SED values produced by IENDP, IENFP and NENA are 765.61, 804.52 and 817.25, respectively. The SED value produced by the proposed IENDP algorithm is reduced by 4.84% and 6.32% compared with IENFP and NENA algorithms. The iterations used by IENDP, IENFP and NENA for convergence on dataset A are 10, 26 and 102, respectively. And the iteration used by the proposed IENDP is decreased by 61.54% and 90.20% compared with IENFP and NENA. From Fig. 5a, we can see that the SED values produced by these three algorithms are 171.13, 173.43 and 188.87, respectively. The SED value produced by the proposed IENDP algorithm is reduced by 1.33% and 9.39% compared with IENFP and NENA. The iterations used by IENDP, IENFP and NENA for convergence on dataset Sym are 21, 28 and 63, respectively. The iteration used by the proposed IENDP algorithm is decreased by 25.00% and 66.67% compared with IENFP and NENA algorithms.
To further illustrate the impact of the new energy function and the dynamic parameter strategy on algorithm performance, a representative elastic node (neuron) is selected respectively from the NENA, IENFP and the proposed IENDP to show their position changes on the first, second and third dimensions. Here the first, second and third dimension position coordinates of the neurons are denoted by X, Y and Z. The coordinate changes of the first dimension \(\Delta X\), the second dimension \(\Delta Y\) and the third dimension \(\Delta Z\) of the representative neuron in NENA, IENFP and IENDP are tracked. The evolutions of the representative neurons’ position changes for clustering on dataset A and dataset Sym are plotted in Figs. 6 and 7.
As illustrated in Figs. 6 and 7, it is evident that the IENFP and IENDP methods exhibit a rapid convergence, with the coordinate shifts of the neurons diminishing to nearly zero at a rate that surpasses that of NENA. The reasons for this phenomenon are analyzed as follows. Because the object function of clustering is introduced into the energy function of the proposed IENFP and IENDP, and the second item of the energy function in the original elastic net is removed, the forces between adjacent neurons disappear. Consequently, under the influence of the new energy function, the neurons are able to move more faster towards the cluster centers, leading to improved clustering outcomes.
Furthermore, in Figs. 6 and 7, the proposed IENDP converges to a stable state in shorter time. At the initial phase of network operation, the coordinate changes of the neurons of the proposed IENDP in each iteration and the ranges of the neurons’ movements of IENDP are much larger than IENFP and NENA. With the dynamic parameter strategy, the dynamic parameter \(\mu (t)\) is set to a relatively high value during the early stage of network operation. A higher \(\mu (t)\) strengthens the attraction forces from data points to elastic nodes, thereby amplifying the differences among these forces. Consequently, the enhanced attractions lead to greater positional change of elastic nodes in each iteration, enabling them to rapidly approach the correct cluster centers. It effectively accelerates the expansion process of the elastic net. Due to the increment in the changes of neurons’ movements in each iteration, the space searching ability of the network is significantly enhanced. Thus the capacity of IENDP to find the optimal solution is increased. As the network operates, \(\mu (t)\) gradually decreases and stabilizes within an optimal range. This gradual reduction allows sufficient time for IENDP to identify the probability distribution that maximizes entropy under appropriate parameter conditions. In the convergence phase of the network, the dynamic parameter \(\mu (t)\) continuously decreases, which could speed up the decrease of the energy function and the convergence process of IENDP.
Parameter sensitivity analysis

Accuracy and iteration variation curves with different initial parameter values.
In addition, we also analyze the dependence of our algorithm on parameters in this section. The accuracy and iterations of IENDP, IENFP and NENA algorithms on the same two datasets (Sym, Compound) with different initial parameters are shown in Fig. 8. For the Sym dataset, we set the range of parameters \(\mu (t)\) as \(0.001 \le \mu (t) \le 0.02\). And for the Compound dataset, we set the range of parameters \(\mu (t)\) as \(0.006 \le \mu (t) \le 0.016\). From Fig. 8, we can obtain that the average accuracy produced by IENDP, IENFP and NENA on dataset Sym are 0.9326, 0.9200 and 0.8240, respectively. And the average iterations used by each of these three methods on Sym dataset are 9, 102, 167. The average accuracy of the proposed algorithm is increased by 1.37% and 13.18% compared with IENFP and NENA, respectively. And the average iteration used by the proposed method is decreased by 91.18% and 94.61%, respectively. Similarly, on Compound dataset the average accuracy produced by each of the three algorithms is 0.8745, 0.8517 and 0.8426, and the average iteration used by each of the three algorithms is 104, 214, 574, respectively. The average accuracy of the proposed algorithm is increased by 2.68% and 3.79%, while the average iteration used by the proposed method is decreased by 51.40% and 81.88% compared with IENFP and NENA.
In summary, the analysis shows that the proposed IENDP method consistently yields solutions with greater accuracy while requiring fewer iterations compared to the IENFP and NENA methods. This suggests that IENDP exhibits reduced sensitivity to the selection of parameter values. Consequently, the challenges associated with parameter tuning and sensitivity inherent in the elastic net can be effectively alleviated through the implementation of the newly designed energy function and the dynamic parameter strategy.


