
Explainable machine learning models of major crop traits from satellite-monitored continent-wide field trial data – Nature Plants
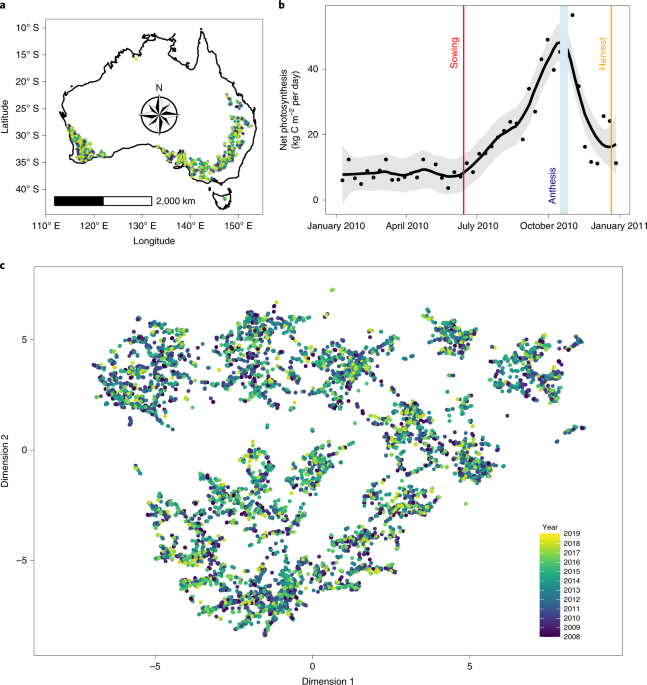
Four species of grass generate half of all human-consumed calories. However, abundant biological data on species that produce our food remain largely inaccessible, imposing direct barriers to understanding crop yield and fitness traits. Here, we assemble and analyse a continent-wide database of field experiments spanning 10 years and hundreds of thousands of machine-phenotyped populations of ten major crop species. Training an ensemble of machine learning models, using thousands of variables capturing weather, ground sensor, soil, chemical and fertilizer dosage, management and satellite data, produces robust cross-continent yield models exceeding R2 = 0.8 prediction accuracy. In contrast to ‘black box’ analytics, detailed interrogation of these models reveals drivers of crop behaviour and complex interactions predicting yield and agronomic traits. These results demonstrate the capacity of machine learning models to interrogate large datasets, generate new and testable outputs and predict crop behaviour, highlighting the powerful role of data in the future of food.
Data availability
All data are available from the Supplementary Information, the linked database descriptor publication5 uploaded to Scientific Data and the figshare7 repository, after screening under our own extensive imputations and quality controls and freely available for research or non-commercial purposes under a CC-BY-NC 3.0 license. Some data available in this repository5 are, alternately, available as a dataset on the Grains Research and Development Corporation website published under a CC-BY-NC 3.0 AU license. The dataset is based predominantly on data sourced from GRDC and GRDC’s extensive investment in the collection, development and presentation of that dataset is acknowledged; however, the dataset has not been subject to GRDC’s quality control processes, does not include updates and corrections that have been made to the dataset and as such may be unreliable such that results of research based on the dataset should not be relied on for any purpose; and any person wishing to conduct research using the original NVT data must approach GRDC directly with a research proposal, noting that terms and conditions may apply. Alternately, the extensively quality-controlled and imputed figshare repository remains freely accessible for research under a creative commons license7.
Data availability
All data are available from the Supplementary Information, the linked database descriptor publication5 uploaded to Scientific Data and the figshare7 repository, after screening under our own extensive imputations and quality controls and freely available for research or non-commercial purposes under a CC-BY-NC 3.0 license. Some data available in this repository5 are, alternately, available as a dataset on the Grains Research and Development Corporation website published under a CC-BY-NC 3.0 AU license. The dataset is based predominantly on data sourced from GRDC and GRDC’s extensive investment in the collection, development and presentation of that dataset is acknowledged; however, the dataset has not been subject to GRDC’s quality control processes, does not include updates and corrections that have been made to the dataset and as such may be unreliable such that results of research based on the dataset should not be relied on for any purpose; and any person wishing to conduct research using the original NVT data must approach GRDC directly with a research proposal, noting that terms and conditions may apply. Alternately, the extensively quality-controlled and imputed figshare repository remains freely accessible for research under a creative commons license7.
www.nature.com


